

L’IA générative est la forme d’intelligence artificielle la plus en vogue aujourd’hui, et c’est elle qui alimente les chatbots comme ChatGPT, Ernie, LLaMA, Claude et Command, ainsi que les générateurs d’images comme DALL-E 2, Stable Diffusion, Adobe Firefly et Midjourney. L’IA générative est la branche de l’IA qui permet aux machines d’apprendre des modèles à partir de vastes ensembles de données, puis de produire de manière autonome un nouveau contenu basé sur ces modèles. Bien que l’IA générative soit relativement nouvelle, il existe déjà de nombreux exemples de modèles capables de produire du texte, des images, des vidéos et du son.
De nombreux « modèles de base » ont été formés sur suffisamment de données pour être compétents dans une grande variété de tâches. Par exemple, un grand modèle de langage peut générer des essais, du code informatique, des recettes, des structures protéiques, des blagues, des conseils de diagnostic médical et bien plus encore. Il peut également théoriquement générer des instructions pour fabriquer une bombe ou créer une arme biologique, bien que des garanties soient censées empêcher de tels types d’utilisation abusive.
Quelle est la différence entre l’IA, l’apprentissage automatique et l’IA générative ?
L’intelligence artificielle (IA) fait référence à une grande variété d’approches informatiques visant à imiter l’intelligence humaine. L’apprentissage automatique (ML) est un sous-ensemble de l’IA ; il se concentre sur les algorithmes qui permettent aux systèmes d’apprendre des données et d’améliorer leurs performances. Avant l’arrivée de l’IA générative, la plupart des modèles de ML apprenaient des ensembles de données pour effectuer des tâches telles que la classification ou la prédiction. L’IA générative est un type spécialisé de ML impliquant des modèles qui effectuent la tâche de générer du nouveau contenu, s’aventurant dans le domaine de la créativité.
Quelles architectures les modèles d’IA générative utilisent-ils ?
Les modèles génératifs sont construits à l’aide de diverses architectures de réseaux neuronaux, essentiellement la conception et la structure qui définissent la manière dont le modèle est organisé et la manière dont les informations y circulent. Certaines des architectures les plus connues sont les auto-encodeurs variationnels (VAE), les réseaux contradictoires génératifs (GAN) et les transformateurs. C’est l’architecture du transformateur, présentée pour la première fois dans cet article fondateur de Google de 2017, qui alimente les grands modèles de langage actuels. Cependant, l’architecture du transformateur est moins adaptée à d’autres types d’IA générative, comme la génération d’images et d’audio.
Les encodeurs automatiques apprennent des représentations efficaces des données grâce à un cadre d’encodeur-décodeur. L’encodeur compresse les données d’entrée dans un espace de dimension inférieure, appelé espace latent (ou d’incorporation), qui préserve les aspects les plus essentiels des données. Un décodeur peut ensuite utiliser cette représentation compressée pour reconstruire les données originales. Une fois qu’un auto-encodeur a été entraîné de cette manière, il peut utiliser de nouvelles entrées pour générer ce qu’il considère comme les sorties appropriées. Ces modèles sont souvent déployés dans des outils de génération d’images et ont également trouvé leur utilité dans la découverte de médicaments, où ils peuvent être utilisés pour générer de nouvelles molécules dotées des propriétés souhaitées.
Avec les réseaux contradictoires génératifs (GAN), la formation implique un générateur et un discriminateur qui peuvent être considérés comme des adversaires. Le générateur s’efforce de créer des données réalistes, tandis que le discriminateur vise à faire la distinction entre les résultats générés et les véritables résultats de « vérité terrain ». Chaque fois que le discriminateur capte une sortie générée, le générateur utilise ce retour pour tenter d’améliorer la qualité de ses sorties. Mais le discriminateur reçoit également un feedback sur ses performances. Cette interaction contradictoire aboutit au raffinement des deux composants, conduisant à la génération d’un contenu d’apparence de plus en plus authentique. Les GAN sont surtout connus pour créer des deepfakes, mais peuvent également être utilisés pour des formes plus bénignes de génération d’images et de nombreuses autres applications.
Le transformateur est sans doute le champion en titre des architectures d’IA génératives en raison de son omniprésence dans les puissants grands modèles de langage (LLM) actuels. Sa force réside dans son mécanisme d’attention, qui permet au modèle de se concentrer sur différentes parties d’une séquence d’entrée tout en faisant des prédictions. Dans le cas des modèles de langage, l’entrée est constituée de chaînes de mots qui composent des phrases, et le transformateur prédit quels mots viendront ensuite (nous entrerons dans les détails ci-dessous). De plus, les transformateurs peuvent traiter tous les éléments d’une séquence en parallèle plutôt que de la parcourir du début à la fin, comme le faisaient les types de modèles précédents ; cette parallélisation rend la formation plus rapide et plus efficace. Lorsque les développeurs ont ajouté de vastes ensembles de données de texte pour permettre aux modèles de transformateurs d’apprendre, les remarquables chatbots d’aujourd’hui ont émergé.
Comment fonctionnent les grands modèles de langage ?
Un LLM basé sur un transformateur est formé en lui fournissant un vaste ensemble de données de texte à partir duquel apprendre. Le mécanisme d’attention entre en jeu lorsqu’il traite les phrases et recherche des modèles. En examinant tous les mots d’une phrase à la fois, il commence progressivement à comprendre quels mots se retrouvent le plus souvent ensemble et quels mots sont les plus importants pour le sens de la phrase. Il apprend ces choses en essayant de prédire le mot suivant dans une phrase et en comparant sa supposition à la vérité terrain. Ses erreurs agissent comme des signaux de rétroaction qui amènent le modèle à ajuster les pondérations qu’il attribue à différents mots avant de réessayer.
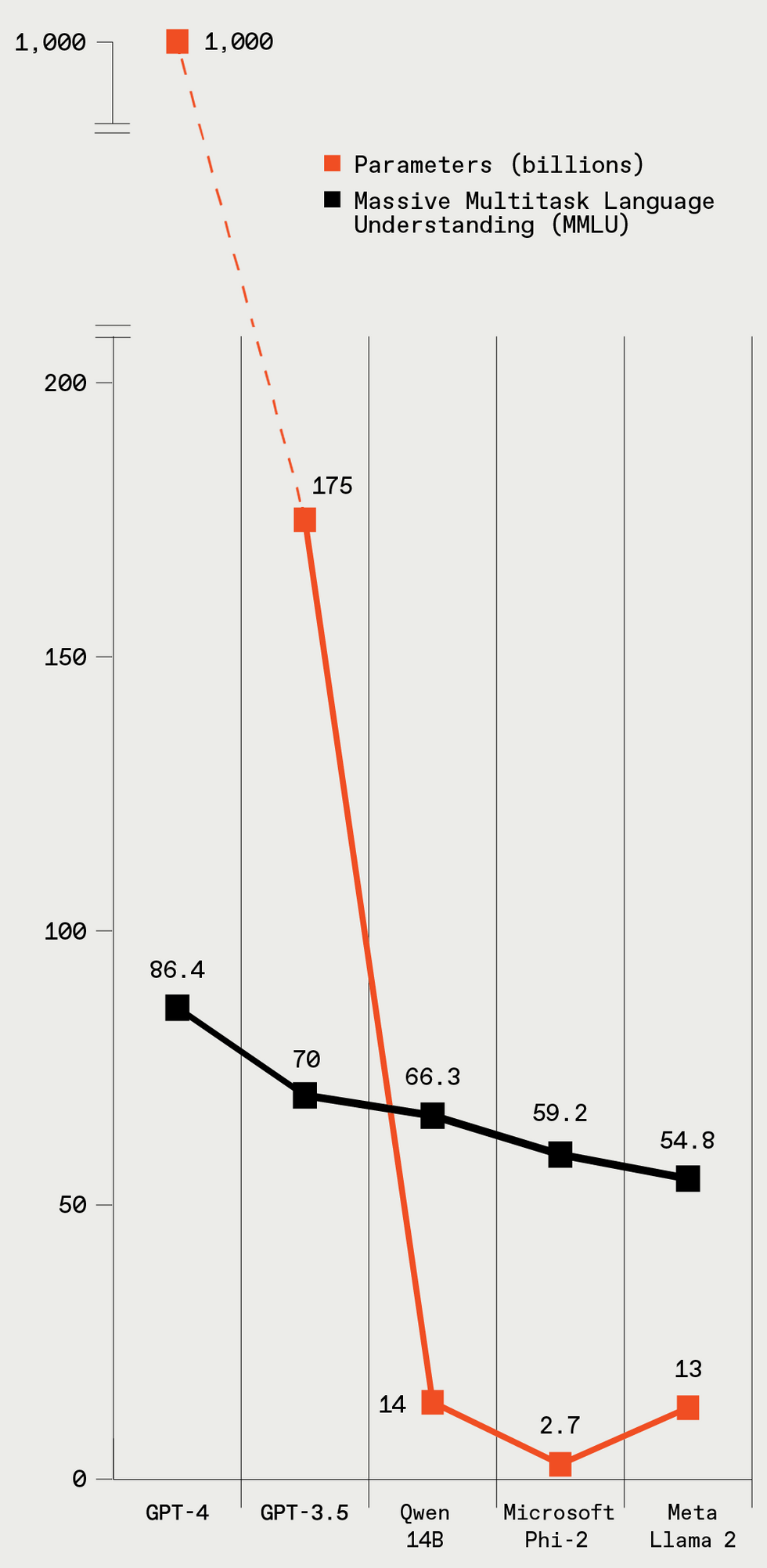 Ces cinq LLM varient considérablement en taille (données en paramètres), et les modèles plus grands ont de meilleures performances lors d’un test de référence LLM standard. Spectre IEEE
Ces cinq LLM varient considérablement en taille (données en paramètres), et les modèles plus grands ont de meilleures performances lors d’un test de référence LLM standard. Spectre IEEE
Pour expliquer le processus de formation en termes légèrement plus techniques, le texte des données de formation est décomposé en éléments appelés jetons, qui sont des mots ou des morceaux de mots. Mais par souci de simplicité, disons que tous les jetons sont des mots. Au fur et à mesure que le modèle parcourt les phrases de ses données d’entraînement et apprend les relations entre les jetons, il crée une liste de nombres, appelée vecteur, pour chacun d’entre eux. Tous les nombres du vecteur représentent divers aspects du mot : ses significations sémantiques, sa relation avec d’autres mots, sa fréquence d’utilisation, etc. Des mots similaires, comme élégant et fantaisie, auront des vecteurs similaires et seront également proches les uns des autres dans l’espace vectoriel. Ces vecteurs sont appelés intégrations de mots. Les paramètres d’un LLM incluent les poids associés à tous les intégrations de mots et au mécanisme d’attention. GPT-4, le modèle OpenAI considéré comme le champion actuel, aurait plus de 1 000 milliards de paramètres.
Avec suffisamment de données et de temps de formation, le LLM commence à comprendre les subtilités du langage. Même si une grande partie de la formation consiste à examiner le texte phrase par phrase, le mécanisme d’attention capture également les relations entre les mots tout au long d’une séquence de texte plus longue composée de plusieurs paragraphes. Une fois qu’un LLM est formé et prêt à être utilisé, le mécanisme d’attention est toujours en jeu. Lorsque le modèle génère du texte en réponse à une invite, il utilise ses pouvoirs prédictifs pour décider quel devrait être le mot suivant. Lors de la génération de morceaux de texte plus longs, il prédit le mot suivant dans le contexte de tous les mots qu’il a écrits jusqu’à présent ; cette fonction augmente la cohérence et la continuité de son écriture.
Pourquoi les grands modèles de langage hallucinent-ils ?
Vous avez peut-être entendu dire que les LLM « hallucinent » parfois. C’est une manière polie de dire qu’ils inventent des choses de manière très convaincante. Un modèle génère parfois un texte qui correspond au contexte et qui est grammaticalement correct, mais le contenu est erroné ou absurde. Cette mauvaise habitude découle de la formation des LLM sur de vastes quantités de données tirées d’Internet, dont beaucoup ne sont pas exactes sur le plan factuel. Étant donné que le modèle essaie simplement de prédire le mot suivant dans une séquence en fonction de ce qu’il a vu, il peut générer un texte plausible qui n’a aucun fondement dans la réalité.
Pourquoi l’IA générative est-elle controversée ?
L’une des sources de controverse autour de l’IA générative est la provenance de ses données d’entraînement. La plupart des entreprises d’IA qui entraînent de grands modèles pour générer du texte, des images, des vidéos et de l’audio n’ont pas été transparentes quant au contenu de leurs ensembles de données de formation. Diverses fuites et expériences ont révélé que ces ensembles de données contiennent du matériel protégé par le droit d’auteur, tel que des livres, des articles de journaux et des films. Un certain nombre de poursuites sont en cours pour déterminer si l’utilisation de matériel protégé par le droit d’auteur pour la formation de systèmes d’IA constitue une utilisation équitable ou si les sociétés d’IA doivent payer les détenteurs de droits d’auteur pour l’utilisation de leur matériel.
Dans le même ordre d’idées, de nombreuses personnes craignent que l’utilisation généralisée de l’IA générative ne supprime les emplois des créatifs qui créent de l’art, de la musique, des œuvres écrites, etc. Les gens craignent également que cela ne supprime les emplois des humains qui effectuent un large éventail de tâches de col blanc, notamment les traducteurs, les parajuristes, les représentants du service client et les journalistes. Il y a déjà eu quelques licenciements inquiétants, mais il est difficile de dire si l’IA générative sera suffisamment fiable pour les applications d’entreprise à grande échelle. (Voir ci-dessus à propos des hallucinations.)
Enfin, il existe un risque que l’IA générative soit utilisée pour créer de mauvaises choses. Et il existe bien sûr de nombreuses catégories de mauvaises choses pour lesquelles elles pourraient théoriquement être utilisées. L’IA générative peut être utilisée pour des escroqueries personnalisées et des attaques de phishing : par exemple, en utilisant le « clonage vocal », les escrocs peuvent copier la voix d’une personne spécifique et appeler sa famille pour lui demander de l’aide (et de l’argent). Tous les formats d’IA générative (texte, audio, image et vidéo) peuvent être utilisés pour générer de la désinformation en créant des représentations apparemment plausibles de choses qui ne se sont jamais produites, ce qui constitue une possibilité particulièrement inquiétante en matière d’élections. (Pendant ce temps, comme IEEE Spectre rapporté cette semaine, la Commission fédérale des communications des États-Unis a réagi en interdisant les appels automatisés générés par l’IA.) Les outils de génération d’images et de vidéos peuvent être utilisés pour produire de la pornographie non consensuelle, bien que les outils créés par les grandes entreprises interdisent une telle utilisation. Et les chatbots peuvent théoriquement guider un terroriste potentiel à travers les étapes de fabrication d’une bombe, de gaz neurotoxiques et d’une foule d’autres horreurs. Bien que les grands LLM disposent de garanties pour empêcher de telles utilisations abusives, certains pirates informatiques prennent plaisir à contourner ces garanties. De plus, des versions « non censurées » de LLM open source existent.
Malgré ces problèmes potentiels, nombreux sont ceux qui pensent que l’IA générative peut également rendre les gens plus productifs et pourrait être utilisée comme un outil permettant de créer de toutes nouvelles formes de créativité. Nous assisterons probablement à des catastrophes, à des floraisons créatives et à bien d’autres choses auxquelles nous ne nous attendons pas. Mais connaître les bases du fonctionnement de ces modèles est aujourd’hui de plus en plus crucial pour les personnes férus de technologie. Parce que peu importe le degré de sophistication de ces systèmes, c’est le travail des humains de les faire fonctionner, d’améliorer les suivants et, avec un peu de chance, d’aider également les gens.