

Die Zeiten ändern sich und damit auch die Kriterien. Jetzt, da wir uns fest im Zeitalter der massiven generativen KI befinden, ist es an der Zeit, zwei dieser Giganten, Llama 2 70B und Stable Diffusion XL, zu den Inferenztests von MLPerf hinzuzufügen. Version 4.0 des Benchmarks testet mehr als 8.500 Ergebnisse von 23 einreichenden Organisationen. Wie schon von Anfang an schnitten Computer mit Nvidia-GPUs an der Spitze ab, insbesondere solche mit dem H200-Prozessor. Aber auch KI-Beschleuniger von Intel und Qualcomm waren mit dabei.
MLPerf begann letztes Jahr mit dem Einstieg in die LLM-Welt durch die Hinzufügung eines GPT-J-Textzusammenfassungs-Benchmarks (ein Open-Source-Modell mit 6 Milliarden Parametern). Mit 70 Milliarden Parametern ist Llama 2 eine Größenordnung größer. Dies erfordert also, was der Organisator MLCommons, ein in San Francisco ansässiges KI-Konsortium, „eine andere Klasse von Hardware“ nennt.
„In Bezug auf die Modellparameter stellt Llama-2 eine dramatische Steigerung gegenüber den Modellen in der Inferenzsuite dar“, sagte Mitchelle Rasquinha, Softwareentwickler bei Google und Co-Vorsitzender der MLPerf Inference-Arbeitsgruppe, in einer Pressemitteilung.
Stable Diffusion XL, der neue Maßstab für die Text-zu-Bild-Generierung, verfügt über 2,6 Milliarden Parameter, weniger als halb so groß wie GPT-J. Der im letzten Jahr überarbeitete Empfehlungssystemtest ist umfassender als beide.
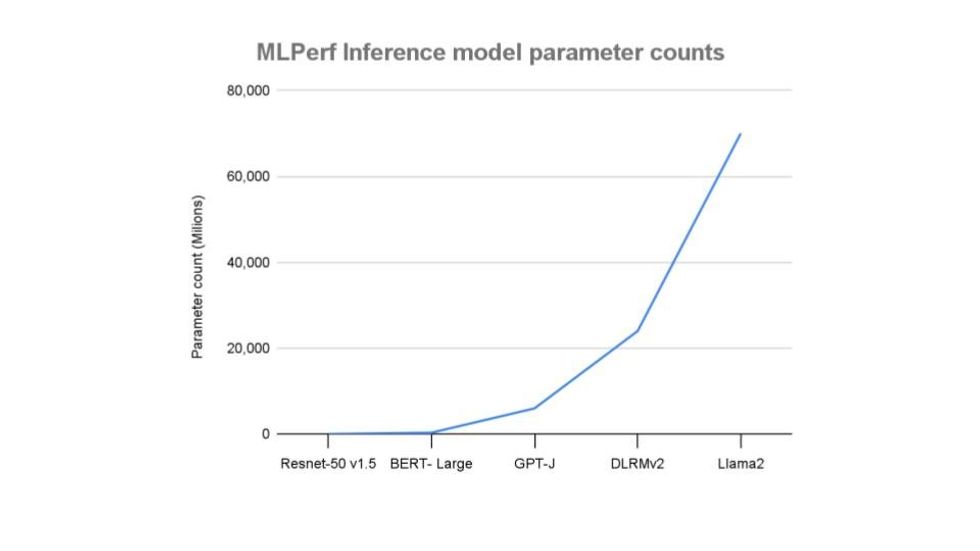 MLPerf-Benchmarks decken den gesamten Größenbereich ab, wobei die neuesten wie Llama 2 70B mehrere zehn Milliarden Parameter umfassen.MLCommons
MLPerf-Benchmarks decken den gesamten Größenbereich ab, wobei die neuesten wie Llama 2 70B mehrere zehn Milliarden Parameter umfassen.MLCommons
Die Tests werden aufgeteilt zwischen Systemen, die für den Einsatz in Rechenzentren vorgesehen sind, und solchen, die für den Einsatz durch Geräte auf der ganzen Welt oder „Edge“, wie es genannt wird, vorgesehen sind. Für jeden Benchmark kann ein Computer im sogenannten Offline-Modus oder auf realistischere Weise getestet werden. Im Offline-Modus durchläuft es die Testdaten so schnell wie möglich, um den maximalen Durchsatz zu ermitteln. Die realistischsten Tests zielen darauf ab, Dinge wie einen Datenstrom von einer Kamera in einem Smartphone, mehrere Datenströme von allen Kameras und Sensoren in einem Auto oder Abfragen in einem Auto-Rechenzentrum zu simulieren. Zusätzlich wurde der Stromverbrauch einiger Systeme während der Aufgaben überwacht.
Ergebnisse der Rechenzentrumsinferenz
Spitzenreiter in den neuen generativen KI-Kategorien war ein Nvidia H200-System, das acht GPUs mit zwei Intel Xeon-Prozessoren kombiniert. Es verarbeitete knapp 14 Anfragen pro Sekunde für Stable Diffusion und rund 27.000 Token pro Sekunde für Llama 2 70B. Seine engsten Konkurrenten waren die 8-GPU-H100-Systeme. Und der Leistungsunterschied war bei Stable Diffusion nicht groß, etwa 1 Anfrage pro Sekunde, aber der Unterschied war bei Llama 2 70B größer.
Die H200 verfügen über die gleiche Hopper-Architektur wie die H100, jedoch mit etwa 75 % mehr Speicher mit hoher Bandbreite und 43 % mehr Speicherbandbreite. Laut Dave Salvator von Nvidia ist der Speicher besonders wichtig bei LLMs, die am besten funktionieren, wenn sie zusammen mit anderen wichtigen Daten vollständig in den Chip passen. Der Speicherunterschied zeigte sich in den Llama 2-Ergebnissen, wo der H200 den H100 um etwa 45 % übertraf.
Nach Angaben des Unternehmens waren mit H100-GPUs ausgestattete Systeme dank Softwareverbesserungen im Vergleich zu den Ergebnissen vom letzten September 2,4 bis 2,9 Mal schneller als H100-Systeme.
Obwohl der H200 der Star von Nvidias Benchmark-Show war, erscheint seine neue GPU-Architektur, Blackwell, die letzte Woche offiziell vorgestellt wurde, im Hintergrund. Salvator würde nicht sagen, wann Computer mit dieser GPU in die Benchmark-Charts einsteigen könnten.
Intel wiederum bot Nvidia weiterhin seinen Gaudi 2-Beschleuniger als einzige Option an, zumindest unter den Unternehmen, die an den Inferenz-Benchmarks von MLPerf teilnahmen. In Bezug auf die Rohleistung lieferte der 7-Nanometer-Intel-Chip knapp die Hälfte der Leistung des 5-nm-H100 in einer 8-GPU-Konfiguration für Stable Diffusion XL. Sein Gaudi 2 lieferte Ergebnisse, die näher an einem Drittel der Leistung von Nvidias Llama 2 70B lagen. Intel behauptet jedoch, dass, wenn man die Leistung pro Dollar misst (was sie selbst gemacht haben, nicht mit MLPerf), der Gaudi 2 in etwa dem H100 entspricht. Für Stable Diffusion schätzt Intel, dass es den H100 um etwa 25 % in der Leistung pro Dollar übertrifft. Für Llama 2 70B ist es entweder ein ausgeglichener Wettbewerb oder 21 % schlechter, je nachdem, ob man im Servermodus oder offline misst.
Der Nachfolger von Gaudi 2, Gaudi 3, wird voraussichtlich noch in diesem Jahr erscheinen.
Intel präsentierte auch mehrere reine CPU-Einträge, die zeigten, dass ohne GPU ein angemessenes Maß an Inferenzleistung möglich war, jedoch nicht mit Llama 2 70B oder Stable Diffusion. Dies war der erste Auftritt von Intel
Ergebnisse der Kanteninferenz
So groß es auch ist, Llama 2 70B wurde nicht in der Edge-Kategorie getestet, Stable Diffusion XL jedoch schon. Hier war das System mit der besten Leistung ein System mit zwei Nvidia L40S-GPUs und einem Intel Xeon-Prozessor. Die Leistung wird hier in Latenz und Samples pro Sekunde gemessen. Das von Wiwynn, einem in Taipeh ansässigen Cloud-Infrastrukturunternehmen, angebotene System lieferte im Single-Stream-Modus Antworten in weniger als 2 Sekunden. Im Offline-Modus generiert es 1,26 Ergebnisse pro Sekunde.
Energieverbrauch
In der Kategorie „Rechenzentren“ traten im Wettbewerb um Energieeffizienz Nvidia und Qualcomm gegeneinander an. Letzteres konzentriert sich seit der Einführung des Cloud AI 100-Prozessors vor über einem Jahr auf energieeffiziente Inferenz. Qualcomm stellte Ende letzten Jahres eine neue Generation von Beschleunigerchips vor, den Cloud AI 100 Ultra, und die ersten Ergebnisse zeigten sich in den oben genannten Edge- und Rechenzentrums-Leistungstests. Im Vergleich zu den Cloud AI 100 Pro-Ergebnissen erzielte Ultra eine 2,5- bis 3-fache Leistungssteigerung und verbrauchte dabei weniger als 150 Watt pro Chip.
Unter den Edge-Inference-Anbietern war Qualcomm das einzige Unternehmen, das Stable Diffusion XL ausprobierte und dabei 0,6 Samples pro Sekunde bei 578 Watt bewältigte.
Aus den Artikeln auf Ihrer Website
Verwandte Artikel im Internet