
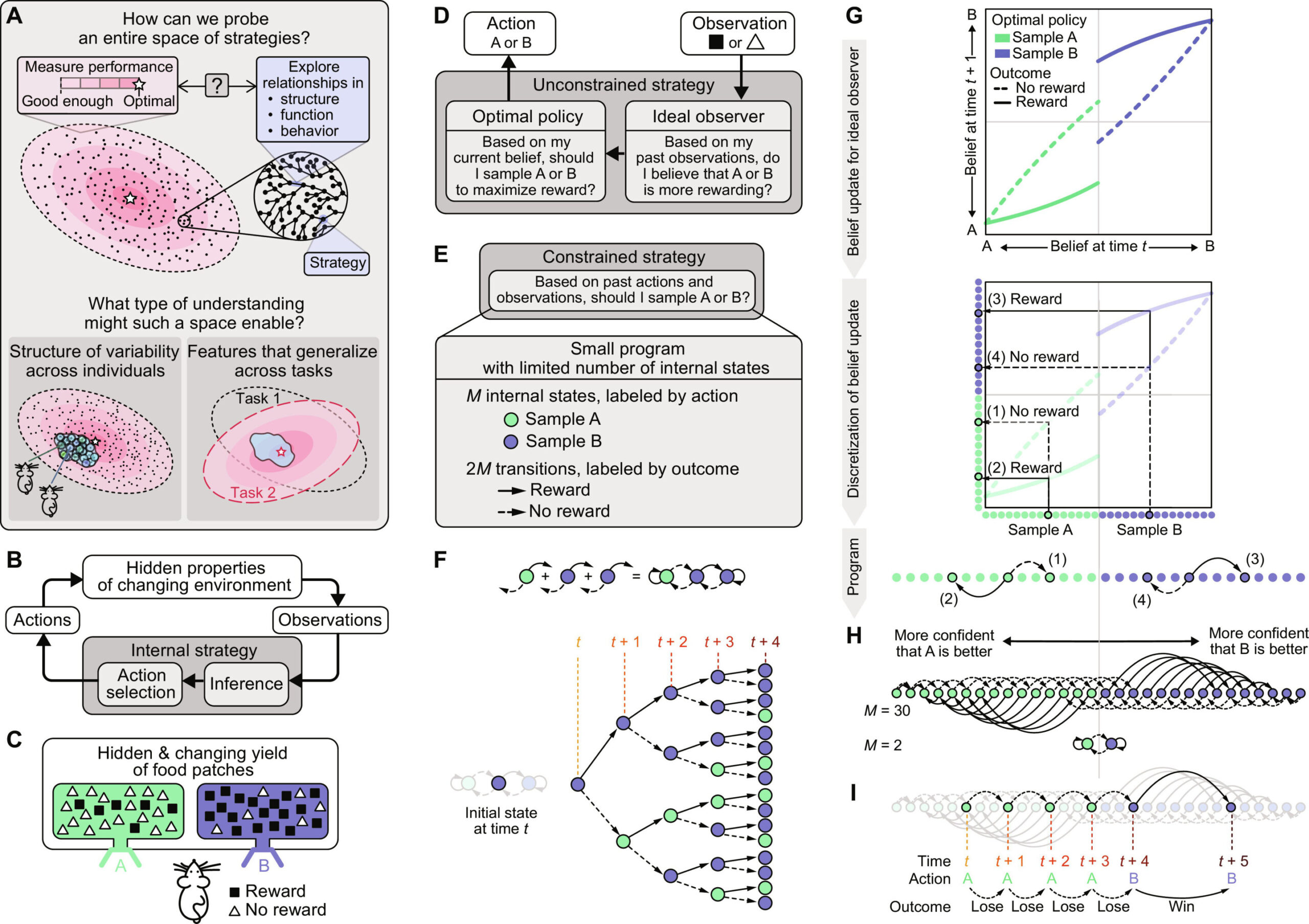
 Oben: Der Spielraum an Strategien zur Lösung einer Aufgabe kann groß sein, wobei viele Strategien eine ausreichend gute Leistung erzielen. Unten: Die Untersuchung der Beziehungen zwischen Strategien könnte Einblicke in die Verhaltensvariabilität von Tieren und Aufgaben liefern. (B) Allgemeine Aufgabenstellung: Ein Tier zieht Rückschlüsse auf verborgene Eigenschaften der Umgebung, um seine Handlungen zu leiten. (C) Spezifische Aufgabenkonfiguration: Ein Tier ernährt sich von zwei Häfen, deren Belohnungswahrscheinlichkeiten sich im Laufe der Zeit ändern. (D) Die uneingeschränkte optimale Strategie besteht aus einer optimalen Richtlinie gekoppelt mit einem Bayes'schen idealen Beobachter. (E) Wir formulieren eine eingeschränkte Strategie als kleines Programm, das eine begrenzte Anzahl interner Zustände verwendet, um Aktionen basierend auf vergangenen Aktionen und Beobachtungen auszuwählen. (F) Jedes Programm generiert Aktionssequenzen basierend auf den Ergebnissen vergangener Aktionen. (G) Die uneingeschränkte optimale Strategie (D) kann in ein kleines Programm übersetzt werden, indem die vom idealen Bayes'schen Beobachter implementierte Glaubensaktualisierung diskretisiert und mit der optimalen Verhaltensrichtlinie gekoppelt wird. Oben: Aktualisierung optimaler Überzeugungen. Mitte: Glaubenswerte können in diskrete Zustände (gefüllte Kreise) unterteilt werden, die durch die von ihnen angegebene Aktion gekennzeichnet sind (blau gegenüber grün). Die Glaubensaktualisierung gibt Übergänge zwischen Zuständen an, abhängig davon, ob eine Belohnung erhalten wurde oder nicht (durchgezogene oder gepunktete Pfeile). Unten: Zustände und Übergänge, dargestellt als Bayesianisches Programm. (H) Oben: Ein 30-Staaten-Programm nähert sich der Bayes'schen Aktualisierung in (G) an und verfügt über zwei Integrationsrichtungen, die als Erhöhung des Vertrauens in die eine oder andere Option interpretiert werden können. Unten: Das Zwei-Staaten-Bayesianische Programm „Win-Stay, Lose-Go“ (WSLG) führt weiterhin die gleiche Aktion aus, wenn es gewinnt (d. h. eine Belohnung erhält) und wechselt die Aktion im Falle eines Verlusts (d. h. keine Belohnung erhalten). (I) Beispiel für ein Verhalten, das durch das 30-Staaten-Bayes-Programm in (H) erzeugt wird. Bildnachweis: Science Advances (2024). DOI: 10.1126/sciadv.adj4064")
Aufbau kompakter Verhaltensprogramme. (A) Oben: Der Spielraum an Strategien zur Lösung einer Aufgabe kann groß sein, wobei viele Strategien eine ausreichend gute Leistung erzielen. Unten: Die Untersuchung der Beziehungen zwischen Strategien könnte Einblicke in die Verhaltensvariabilität von Tieren und Aufgaben liefern. (B) Allgemeine Aufgabenstellung: Ein Tier zieht Rückschlüsse auf verborgene Eigenschaften der Umgebung, um seine Handlungen zu leiten. (C) Spezifische Aufgabenkonfiguration: Ein Tier ernährt sich von zwei Häfen, deren Belohnungswahrscheinlichkeiten sich im Laufe der Zeit ändern. (D) Die uneingeschränkte optimale Strategie besteht aus einer optimalen Richtlinie gekoppelt mit einem Bayes’schen idealen Beobachter. (E) Wir formulieren eine eingeschränkte Strategie als kleines Programm, das eine begrenzte Anzahl interner Zustände verwendet, um Aktionen basierend auf vergangenen Aktionen und Beobachtungen auszuwählen. (F) Jedes Programm generiert Aktionssequenzen basierend auf den Ergebnissen vergangener Aktionen. (G) Die uneingeschränkte optimale Strategie (D) kann in ein kleines Programm übersetzt werden, indem die vom idealen Bayes’schen Beobachter implementierte Glaubensaktualisierung diskretisiert und mit der optimalen Verhaltensrichtlinie gekoppelt wird. Oben: Aktualisierung optimaler Überzeugungen. Mitte: Glaubenswerte können in diskrete Zustände (gefüllte Kreise) unterteilt werden, die durch die von ihnen angegebene Aktion gekennzeichnet sind (blau gegenüber grün). Die Glaubensaktualisierung gibt Übergänge zwischen Zuständen an, abhängig davon, ob eine Belohnung erhalten wurde oder nicht (durchgezogene oder gepunktete Pfeile). Unten: Zustände und Übergänge, dargestellt als Bayesianisches Programm. (H) Oben: Ein 30-Staaten-Programm nähert sich der Bayes’schen Aktualisierung in (G) an und verfügt über zwei Integrationsrichtungen, die als Erhöhung des Vertrauens in die eine oder andere Option interpretiert werden können. Unten: Das bayesianische Zwei-Staaten-Programm Win-Stay, Lose-Go (WSLG) führt weiterhin die gleiche Aktion aus, wenn es gewinnt (d. h. eine Belohnung erhält) und wechselt die Aktion im Falle eines Verlusts (d. h. keine Belohnung erhalten). (I) Beispiel für ein Verhalten, das durch das 30-Staaten-Bayes-Programm in (H) erzeugt wird. Kredit: Wissenschaftler machen Fortschritte (2024). DOI: 10.1126/sciadv.adj4064
Wenn Neurowissenschaftler über die Strategie nachdenken, die ein Tier anwenden könnte, um eine Aufgabe zu erfüllen (z. B. Nahrung finden, Beute jagen oder durch ein Labyrinth navigieren), kommen sie oft auf ein einziges Modell, das dem Tier die beste Möglichkeit bietet, diese Aufgabe zu erfüllen diese Aufgabe.
Aber in der realen Welt wenden Tiere – und Menschen – möglicherweise nicht die optimale Methode an, was ressourcenintensiv sein kann. Stattdessen verwenden sie eine Strategie, die effektiv genug ist, um die Aufgabe zu erledigen, aber viel weniger Gehirnleistung erfordert.
In einer neuen Studie veröffentlicht in Wissenschaftler machen FortschritteJanelia-Wissenschaftler wollten besser verstehen, wie ein Tier über eine einfache Strategie hinaus ein Problem erfolgreich lösen kann.
Die Arbeit zeigt, dass es für ein Tier eine Vielzahl von Möglichkeiten gibt, eine einfache Aufgabe der Nahrungssuche zu erfüllen. Es stellt außerdem einen theoretischen Rahmen für das Verständnis dieser unterschiedlichen Strategien dar, wie sie zueinander in Beziehung stehen und wie sie dasselbe Problem unterschiedlich lösen.
Einige dieser unvollkommenen Optionen zur Bewältigung einer Aufgabe funktionieren fast genauso gut wie die optimale Strategie, aber mit viel weniger Aufwand, stellten die Forscher fest, wodurch den Tieren die Möglichkeit gegeben wird, wertvolle Ressourcen für die Bewältigung mehrerer Aufgaben zu nutzen.
„Sobald man sich von der Perfektion befreit, wird man überrascht sein, wie viele Möglichkeiten es gibt, ein Problem zu lösen“, sagt Tzuhsuan Ma, Postdoktorand am Hermundstad Lab, der die Forschung leitete.
Der neue Rahmen könnte Forschern helfen, diese „gut genug“-Strategien zu untersuchen, einschließlich der Frage, warum verschiedene Personen unterschiedliche Strategien anpassen könnten, wie diese Strategien zusammenarbeiten könnten und inwieweit die Strategien auf andere Aufgaben übertragbar sind. Dies könnte helfen zu erklären, wie das Gehirn Verhalten in der realen Welt ermöglicht.
„Viele dieser Strategien sind Möglichkeiten, mit denen wir dieses Problem nie lösen könnten, aber sie funktionieren gut, sodass es durchaus möglich ist, dass Tiere sie auch nutzen“, sagt Ann Hermundstad, Leiterin der Janelia-Gruppe. „Sie geben uns ein neues Vokabular, um Verhalten zu verstehen.“
Schauen Sie über die Perfektion hinaus
Die Forschung begann vor drei Jahren, als Ma sich über die verschiedenen Strategien Gedanken machte, die ein Tier möglicherweise anwenden könnte, um eine einfache, aber häufige Aufgabe zu erfüllen: die Wahl zwischen zwei Optionen, deren Chancen auf Belohnung sich mit der Zeit ändern.
Die Forscher wollten eine Gruppe von Strategien untersuchen, die zwischen optimalen Lösungen und völlig zufälligen Lösungen liegen: „kleine Programme“ mit begrenzten Ressourcen, die aber trotzdem ihre Arbeit erledigen. Jedes Programm spezifiziert einen anderen Algorithmus, um die Handlungen eines Tieres auf der Grundlage früherer Beobachtungen zu steuern und so als Modell für das Verhalten des Tieres zu dienen.
Es stellt sich heraus, dass es viele solcher Programme gibt: etwa eine Viertelmillion. Um diese Strategien zu verstehen, untersuchten die Forscher zunächst einige der erfolgreichsten. Überraschenderweise stellten sie fest, dass sie im Wesentlichen das Gleiche taten wie die optimale Strategie, obwohl sie weniger Ressourcen verbrauchten.
„Wir waren ein wenig enttäuscht“, sagt Ma. „Wir haben die ganze Zeit damit verbracht, diese kleinen Programme zu erforschen, und sie folgen alle der gleichen Berechnung, von der das Fach bereits wusste, dass sie ohne all diesen Aufwand mathematisch abgeleitet werden kann.“
Aber die Forscher waren motiviert, weiter zu suchen: Sie hatten eine starke Intuition, dass es Programme geben musste, die gut waren, sich aber von der optimalen Strategie unterschieden. Nachdem sie über die Top-Programme hinausgeschaut hatten, fanden sie, wonach sie suchten: etwa 4.000 Programme, die in die Kategorie „ziemlich gut“ fielen. Und was noch wichtiger ist: Über 90 % von ihnen haben etwas Neues gemacht.
Sie hätten dort aufhören können, aber eine Frage eines anderen Janelianers brachte sie zum Nachdenken: Wie konnten sie erkennen, welche Strategie ein Tier anwendete?
Die Frage veranlasste das Team, tiefer in das Verhalten einzelner Programme einzutauchen und einen systematischen Ansatz zum Nachdenken über Gesamtstrategien zu entwickeln. Sie entwickelten zunächst eine mathematische Methode zur Beschreibung der Beziehungen zwischen Programmen durch ein Netzwerk, das die verschiedenen Programme verbindet. Als nächstes untersuchten sie das durch die Strategien beschriebene Verhalten und entwarfen einen Algorithmus, um aufzudecken, wie sich eines dieser „gut genug“-Programme aus einem anderen entwickeln könnte.
Sie fanden heraus, dass kleine Änderungen am optimalen Programm zu großen Verhaltensänderungen bei gleichzeitiger Beibehaltung der Leistung führen können. Wenn einige dieser neuen Verhaltensweisen auch bei anderen Aufgaben nützlich sind, deutet dies darauf hin, dass dasselbe Programm ausreichen könnte, um eine ganze Reihe unterschiedlicher Probleme zu lösen.
„Wenn man sich vorstellt, dass ein Tier kein Spezialist ist, der darauf optimiert ist, ein einzelnes Problem zu lösen, sondern eher ein Generalist, der viele Probleme löst, ist das wirklich eine neue Art, das zu untersuchen“, sagt Ma.
Diese neue Arbeit bietet Forschern einen Rahmen, um über einzelne, optimale Programme für das Verhalten von Tieren hinauszudenken. Das Team konzentriert sich nun darauf, zu untersuchen, wie gut sich die kleinen Programme auf andere Aufgaben übertragen lassen, und neue Experimente zu entwerfen, um festzustellen, welches Programm ein Tier verwenden könnte, um eine Aufgabe in Echtzeit auszuführen. Sie arbeiten auch mit anderen Janelia-Forschern zusammen, um ihren theoretischen Rahmen zu testen.
„Letztendlich ist ein gutes Verständnis des Verhaltens von Tieren eine wesentliche Voraussetzung für das Verständnis, wie das Gehirn verschiedene Arten von Problemen löst, darunter auch einige, die unsere besten künstlichen Systeme wenn überhaupt nur ineffizient lösen.“ „Die größte Herausforderung besteht darin, dass Tiere möglicherweise ganz andere Strategien anwenden, als wir zunächst annehmen, und diese Arbeit hilft uns, diesen Raum an Möglichkeiten aufzudecken.“
Mehr Informationen:
Tzuhsuan Ma et al, Ein riesiger Raum kompakter Strategien für effektive Entscheidungen, Wissenschaftler machen Fortschritte (2024). DOI: 10.1126/sciadv.adj4064
Bereitgestellt vom Howard Hughes Medical Institute
Zitat: Neue Forschungsergebnisse zeigen, warum man nicht perfekt sein muss, um den Job zu erledigen (24. Juni 2024), abgerufen am 24. Juni 2024 von https://phys.org/news/2024-06-dont-job.html
Dieses Dokument unterliegt dem Urheberrecht. Mit Ausnahme der fairen Nutzung für private Studien- oder Forschungszwecke darf kein Teil ohne schriftliche Genehmigung reproduziert werden. Der Inhalt dient lediglich der Information.