

En 1997, le IBM Bleu Profond Un superordinateur a vaincu le champion du monde d’échecs Garry Kasparov. Il s’agissait d’une démonstration révolutionnaire de la technologie des superordinateurs et d’un premier aperçu de la manière dont le calcul haute performance pourrait un jour dépasser l’humain–niveau d’intelligence. Au cours des 10 années qui ont suivi, nous avons commencé à utiliser l’intelligence artificielle pour de nombreuses tâches pratiques., comme la reconnaissance faciale, la traduction linguistique et la recommandation de films et de produits dérivés.
Une décennie et demie plus tard, l’intelligence artificielle a progressé au point où elle peut « synthétiser les connaissances ». L’IA générative, telle que ChatGPT et Stable Diffusion, peut composer des poèmes, créer des œuvres d’art, diagnostiquer des maladies, rédiger des rapports de synthèse et du code informatique, et même concevoir des circuits intégrés qui rivalisent avec ceux fabriqués par les humains.
D’énormes opportunités s’offrent à l’intelligence artificielle pour devenir un assistant numérique de toutes les activités humaines. ChatGPT est un bon exemple de la façon dont l’IA a démocratisé l’utilisation du calcul haute performance, offrant ainsi des avantages à chaque individu de la société.
Toutes ces merveilleuses applications de l’IA sont dues à trois facteurs : les innovations dans les algorithmes d’apprentissage automatique efficaces, la disponibilité d’énormes quantités de données sur lesquelles former les réseaux neuronaux et les progrès de l’informatique économe en énergie grâce aux progrès de la technologie des semi-conducteurs. Cette dernière contribution à la révolution de l’IA générative n’a pas reçu sa juste part de crédit, malgré son omniprésence.
Au cours des trois dernières décennies, les étapes majeures de l’IA ont toutes été rendues possibles par la technologie de pointe des semi-conducteurs de l’époque et auraient été impossibles sans elle. Deep Blue a été mis en œuvre avec un mélange de technologies de fabrication de puces à nœuds de 0,6 et 0,35 micromètres. Le réseau neuronal profond qui a remporté le concours ImageNet, ouvrant l’ère actuelle de l’apprentissage automatique, a été mis en œuvre avec une technologie de 40 nanomètres. AlphaGo a conquis le jeu de Go en utilisant la technologie 28 nm, et la version initiale de ChatGPT a été formée sur des ordinateurs construits avec la technologie 5 nm. L’incarnation la plus récente de ChatGPT est alimentée par des serveurs utilisant une technologie 4 nm encore plus avancée. Chaque couche des systèmes informatiques impliqués, depuis les logiciels et algorithmes jusqu’à l’architecture, la conception des circuits et la technologie des appareils, agit comme un multiplicateur des performances de l’IA. Mais il est juste de dire que la technologie fondamentale des transistors est ce qui a permis l’avancement des couches supérieures.
Si la révolution de l’IA veut se poursuivre au rythme actuel, elle aura besoin d’encore plus de la part de l’industrie des semi-conducteurs. D’ici une décennie, il lui faudra un GPU doté de 1 000 milliards de transistors, c’est-à-dire un GPU avec 10 fois plus de périphériques qu’aujourd’hui.
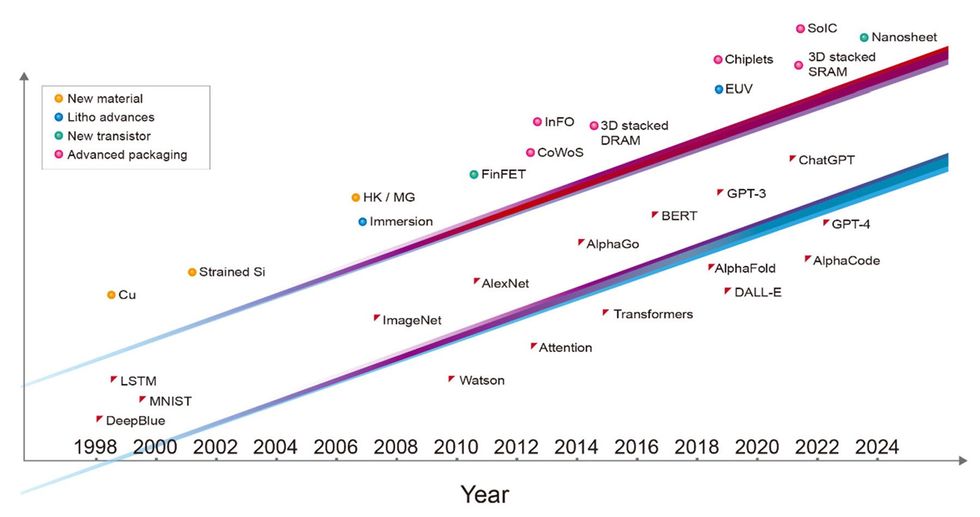 Avancées dans la technologie des semi-conducteurs [top line]— notamment de nouveaux matériaux, les progrès de la lithographie, de nouveaux types de transistors et un conditionnement avancé — ont stimulé le développement de systèmes d’IA plus performants [bottom line]
Avancées dans la technologie des semi-conducteurs [top line]— notamment de nouveaux matériaux, les progrès de la lithographie, de nouveaux types de transistors et un conditionnement avancé — ont stimulé le développement de systèmes d’IA plus performants [bottom line]
Croissance incessante de la taille des modèles d’IA
Les calculs et l’accès à la mémoire requis pour la formation en IA ont augmenté de plusieurs ordres de grandeur au cours des cinq dernières années. La formation GPT-3, par exemple, nécessite l’équivalent de plus de 5 milliards de milliards d’opérations par seconde de calcul pendant une journée entière (soit 5 000 pétaflops-jours) et 3 000 milliards d’octets (3 téraoctets) de capacité de mémoire.
La puissance de calcul et l’accès à la mémoire nécessaires aux nouvelles applications d’IA générative continuent de croître rapidement. Nous devons maintenant répondre à une question urgente : comment la technologie des semi-conducteurs peut-elle suivre le rythme ?
Des appareils intégrés aux chipsets intégrés
Depuis l’invention du circuit intégré, la technologie des semi-conducteurs a consisté à réduire la taille des caractéristiques afin de pouvoir regrouper davantage de transistors dans une puce de la taille d’une miniature. Aujourd’hui, l’intégration a atteint un niveau supérieur ; nous allons au-delà de la mise à l’échelle 2D vers l’intégration de systèmes 3D. Nous rassemblons désormais de nombreuses puces dans un système étroitement intégré et massivement interconnecté. Il s’agit d’un changement de paradigme dans l’intégration de la technologie des semi-conducteurs.
À l’ère de l’IA, la capacité d’un système est directement proportionnelle au nombre de transistors intégrés dans ce système. L’une des principales limites réside dans le fait que les outils de fabrication de puces lithographiques ont été conçus pour fabriquer des circuits intégrés d’une taille maximale d’environ 800 millimètres carrés, ce qu’on appelle la limite du réticule. Mais nous pouvons désormais étendre la taille du système intégré au-delà de la limite du réticule de la lithographie. En attachant plusieurs puces sur un interposeur plus grand (un morceau de silicium dans lequel les interconnexions sont intégrées), nous pouvons intégrer un système contenant un nombre beaucoup plus grand de dispositifs que ce qui est possible sur une seule puce. Par exemple, la technologie CoWoS (chip-on-wafer-on-substrate) de TSMC peut accueillir jusqu’à six champs de réticule de puces de calcul, ainsi qu’une douzaine de puces de mémoire à large bande passante (HBM).
Les HBM sont un exemple d’une autre technologie clé de semi-conducteurs qui est de plus en plus importante pour l’IA : la capacité d’intégrer des systèmes en empilant des puces les unes sur les autres, ce que nous appelons chez TSMC. système sur puces intégrées (SoIC). Un HBM se compose d’une pile de puces DRAM interconnectées verticalement au sommet un contrôle circuit intégré logique. Il utilise des interconnexions verticales appelées tà travers-silicon-vjes (TSVs) pour faire passer les signaux à travers chaque puce et des plots de soudure pour former les connexions entre les puces mémoire. Aujourd’hui, les GPU hautes performances utilisent HBMlargement.
À l’avenir, la technologie SoIC 3D peut fournir une « alternative sans problème » à la technologie HBM conventionnelle d’aujourd’hui, offrant une interconnexion verticale beaucoup plus dense entre les puces empilées. Des progrès récents ont montré des structures de test HBM avec 12 couches de puces empilées à l’aide d’une liaison hybride, une connexion cuivre à cuivre avec une densité supérieure à celle que peuvent fournir les bosses de soudure. Lié à basse température sur une puce logique de base plus grande, ce système de mémoire a une épaisseur totale de seulement 600 µm.
Avec un système informatique haute performance composé d’un grand nombre de puces exécutant de grands modèles d’IA, la communication filaire à haut débit peut rapidement limiter la vitesse de calcul. Aujourd’hui, les interconnexions optiques sont déjà utilisées pour connecter les racks de serveurs dans les centres de données. Nous aurons bientôt besoin d’interfaces optiques basées sur la photonique sur silicium, intégrées aux GPU et aux CPU. Cela permettra d’augmenter les bandes passantes économes en énergie et en surface pour une communication optique directe GPU à GPU, de sorte que des centaines de serveurs puissent se comporter comme un seul GPU géant avec une mémoire unifiée. En raison de la demande des applications d’IA, la photonique sur silicium deviendra l’une des technologies génériques les plus importantes de l’industrie des semi-conducteurs.
Vers un GPU à transistors d’un milliard de milliards
Comme indiqué précédemment, les puces GPU typiques utilisées pour la formation de l’IA ont déjà atteint la limite du champ de réticule. Et leur nombre de transistors est d’environ 100 milliards d’appareils. La poursuite de la tendance à l’augmentation du nombre de transistors nécessitera plusieurs puces, interconnectées avec une intégration 2,5D ou 3D, pour effectuer le calcul. L’intégration de plusieurs puces, soit par CoWoS, soit par SoIC et les technologies d’emballage avancées associées, permet d’obtenir un nombre total de transistors par système beaucoup plus important que celui qui pourrait être intégré dans une seule puce. Nous prévoyons que d’ici une décennie, un GPU multichiplet comportera plus de 1 000 milliards de transistors.
Nous devrons relier tous ces chipsets ensemble dans une pile 3D, mais heureusement, l’industrie a pu rapidement réduire le nombre d’interconnexions verticales, augmentant ainsi la densité des connexions. Et il y a encore beaucoup de place pour en faire davantage. Nous ne voyons aucune raison pour laquelle la densité des interconnexions ne pourrait pas croître d’un ordre de grandeur, voire au-delà.
Tendance en matière de performances économes en énergie pour les GPU
Alors, comment toutes ces technologies matérielles innovantes contribuent-elles aux performances d’un système ?
Nous pouvons déjà constater la tendance dans les GPU des serveurs si nous examinons l’amélioration constante d’une métrique appelée performance économe en énergie. L’EEP est une mesure combinée de l’efficacité énergétique et de la vitesse d’un système. Au cours des 15 dernières années, l’industrie des semi-conducteurs a multiplié par trois environ ses performances en matière d’efficacité énergétique tous les deux ans. Nous pensons que cette tendance se poursuivra à des rythmes historiques. Il sera motivé par des innovations provenant de nombreuses sources, notamment les nouveaux matériaux, les technologies de dispositifs et d’intégration, la lithographie ultraviolette extrême (EUV), la conception de circuits, la conception d’architecture de système et la co-optimisation de tous ces éléments technologiques, entre autres.
En particulier, l’augmentation de l’EEP sera rendue possible par les technologies d’emballage avancées dont nous avons discuté ici. De plus, des concepts tels que la co-optimisation système-technologie (STCO), où les différentes parties fonctionnelles d’un GPU sont séparées sur leurs propres chipsets et construites en utilisant les technologies les plus performantes et les plus économiques pour chacune, deviendront de plus en plus critiques.
Un moment Mead-Conway pour les circuits intégrés 3D
En 1978, Carver Mead, professeur au California Institute of Technology, et Lynn Conway de Xerox PARC ont inventé une méthode de conception assistée par ordinateur pour les circuits intégrés. Ils ont utilisé un ensemble de règles de conception pour décrire la mise à l’échelle des puces afin que les ingénieurs puissent facilement concevoir des circuits d’intégration à très grande échelle (VLSI) sans grande connaissance de la technologie des processus.
Ce même type de capacité est nécessaire pour la conception de puces 3D. Aujourd’hui, les concepteurs doivent connaître la conception de puces, la conception d’architecture système et l’optimisation matérielle et logicielle. Les fabricants doivent connaître la technologie des puces, la technologie des circuits intégrés 3D et la technologie d’emballage avancée. Comme nous l’avons fait en 1978, nous avons à nouveau besoin d’un langage commun pour décrire ces technologies d’une manière que les outils de conception électronique comprennent. Un tel langage de description matérielle donne aux concepteurs toute latitude pour travailler sur la conception d’un système IC 3D, quelle que soit la technologie sous-jacente. C’est en route : un standard open source, appelé 3Dblox, a déjà été adopté par la plupart des entreprises technologiques actuelles et des sociétés d’automatisation de la conception électronique (EDA).
L’avenir au-delà du tunnel
À l’ère de l’intelligence artificielle, la technologie des semi-conducteurs constitue un élément clé pour les nouvelles capacités et applications de l’IA. Un nouveau GPU n’est plus limité par les tailles et les facteurs de forme standard du passé. La nouvelle technologie des semi-conducteurs ne se limite plus à réduire les transistors de nouvelle génération sur un plan bidimensionnel. Un système d’IA intégré peut être composé d’autant de transistors économes en énergie que possible, d’une architecture système efficace pour les charges de travail de calcul spécialisées et d’une relation optimisée entre le logiciel et le matériel.
Au cours des 50 dernières années, le développement de la technologie des semi-conducteurs a donné l’impression de marcher dans un tunnel. La route était claire, car il y avait un chemin bien défini. Et tout le monde savait ce qu’il fallait faire : réduire le transistor.
Nous sommes désormais arrivés au bout du tunnel. À partir de là, la technologie des semi-conducteurs deviendra plus difficile à développer. Pourtant, au-delà du tunnel, de nombreuses autres possibilités s’offrent à nous. Nous ne sommes plus liés par les limites du passé.